Noba 是什么?
Noba 是 “not only backtrader” 缩写 😀。该项目是我们另外一个项目 Backtrader_Bokeh 的升级版。取这个名字也是为了强调 backtrader 只是给 Noba 提供量化回测服务,而非核心模块。
Noba 的核心模块是一个 ioc 容器。通过在该容器中注册的服务,用户能够很容易构造出服务实体并提供服务。 量化回测服务在 Noba 中被注册为一个名为 "BB" 的服务。通过生产 "BB" 服务实体,你可以调用我们改良过的 backtrader1 所有功能,然后通过 Bokeh 把回测结果通过网页展示出来。
除了 “BB” 服务,Noba 还自带了另外 3 个服务:事件服务,管道服务,以及一个数据库抽象服务。这些服务在后续章节中我们将详细介绍,在此你只是需要知道通过 ioc 容器,你很容易就获得这些服务实体并使用他们。
当然,你还可以创造自己的服务并注册到 ioc 中,这样你就可以全局创建并使用他们。通过 Noba 的 ioc 容器以及各种服务,你可以让你的量化投资研究更加工程化,通过解耦,你的研究成果也能在不同量化项目中得到很好的复用。
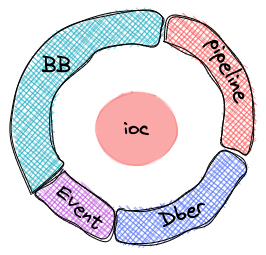
目前 Noba 已的社群:
Github:Noba
微信群:添加微信号 Aui_Team
QQ 群:908547278
TG 群:Aui_Channel
Discord:Aui and Friends
因为 backtrader 存在 bug 以及一些功能上的不足,所以我们通过补丁也对 backtrader 进行了改良
快速上手
本章快速上手只是帮助你整体浏览 Noba 的工作流。详细内容会在后续各章节中进行介绍。
安装
pip install noba
初始化 Noba 项目
mkdir noba_project # 名字随意取
cd noba_project
noba init
* 下面内容是 noba init 初始化过程。本章用 csv 文件示例。除了 csv 和 orcl-1995-2014.txt ,其他直接回车用默认的就好
Let's init Noba project...
connector(mysql/sqLite/postgresql/...) : csv
host(localhost/...) :
port(3306/...) :
database : orcl-1995-2014.txt
username :
password :
format(dataframe/list) :
Demo 数据
- 下载:orcl-1995-2014.txt
- 把 orcl-1995-2014.txt 移动到
noba_project/migrate目录下
编辑 main.py
* 初始化 Noba 项目后,mainy.py已经存在,把下面内容覆盖到 main.py 中
from __future__ import (absolute_import, division, print_function, unicode_literals)
import pandas as pd
from noba import core
from datetime import datetime
bt = core('bb')
class My_PandaData(bt.feeds.PandasData):
params = (
('nullvalue', 0.0),
('dtformat', '%Y-%m-%d'),
('high', 1),
('low', 2),
('open', 0),
('close', 4),
('volume', 5),
('fromdate', datetime(2000, 1, 1),),
('todate', datetime(2001, 2, 28)),
('openinterest',None),
)
class MyStrategy(bt.Strategy):
def __init__(self):
sma1 = bt.indicators.SMA(period=11, subplot=True)
bt.indicators.SMA(period=17, plotmaster=sma1)
bt.indicators.RSI()
def next(self):
pos = len(self.data)
if pos == 45 or pos == 145:
self.buy(self.datas[0], size=None)
if pos == 116 or pos == 215:
self.sell(self.datas[0], size=None)
if __name__ == '__main__':
cerebro = bt.Cerebro()
cerebro.addstrategy(MyStrategy)
db = core('db')
data = db.set_index('Date').get()
data.index = pd.to_datetime(data.index)
datafeed = My_PandaData(dataname = data)
cerebro.adddata(datafeed, name='orcl-1995-2014')
cerebro.addanalyzer(bt.analyzers.SharpeRatio)
cerebro.run()
p = bt.Bokeh()
cerebro.plot(p)
运行项目
python main.py
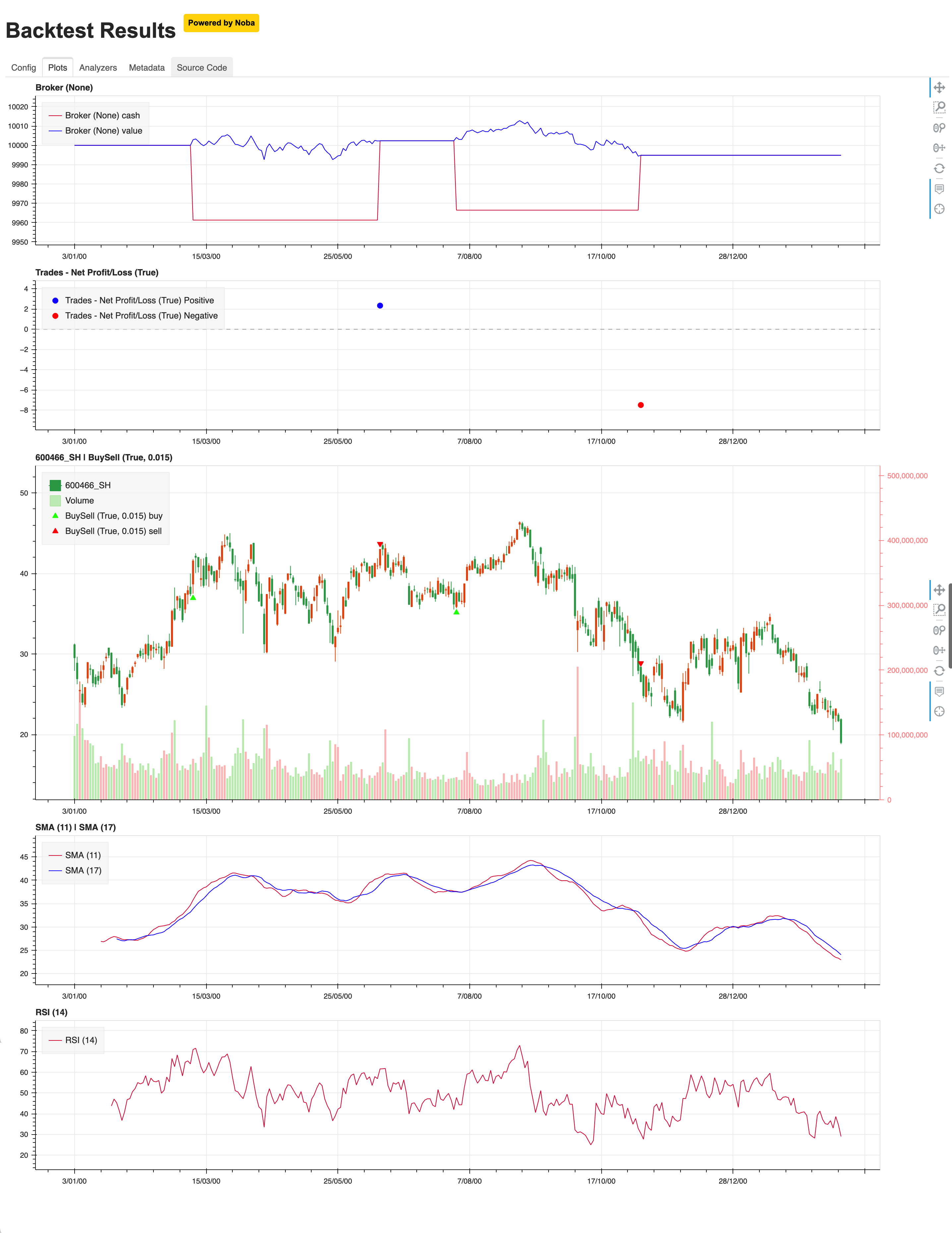
图表展示
* 下面是运行量化回测后的部分截图
安装和初始化
安装方式
- 方式一
pip install noba - 方式二
pip install git+https://github.com/iniself/noba - 方式三
git clone https://github.com/iniself/noba.git cd noba pip install .
初始化项目
-
创建项目
mkdir noba_project cd noba_project noba init -
初始化参数简介
* 本章对各参数仅做简单说明,详情见 数据库抽象服务Let's init Noba project...
connector(mysql/sqLite/postgresql/...) :
host(localhost/...) :
port(3306/...) :
database :
username :
password :
format(dataframe/list) :- 括号中第一个选项是 Noba 的默认。比如 connector 默认是
mysql。通过回车可以选择默认 - 如果希望用某类数据库的默认配置,比如
端口port,请键入空格然后回车 - connector(数据库连接器)。目前支持:
mysql/sqLite/postgresql/csv/xls/mssql/mssql3/mssql4/firebird/oracle/db2/ingres/sybase/informix/teradata/cubrid/sapdb/imap/mongodb - host:数据库位置
- port:数据库端口
- database:要操作的数据库。sqLite 填入文件名
- username:用户名
- password:密码
- format:查询结果的返回格式
- 括号中第一个选项是 Noba 的默认。比如 connector 默认是
最佳实践
* 用 conda 来管理虚拟环境
-
安装
mini-conda* 下面视频我介绍了 conda 的安装,可以直接拉到 7 分钟开始
-
创建 Noba 专用环境 * python > 3.7
conda create -n noba python=3.10.0 -
切换到
noba环境conda activate noba
核心功能
Noba 是一套用于量化研究的脚手架。我们希望用户能够通过项目化方式来组织自己的量化研究。项目化的好处就是:
- 能方便搭建出越来越复杂的回测逻辑
- 用户实现的功能被解耦并有效复用
- 方便集成第三方已经实现的功能
于是 Noba 有了如下 4 个核心功能:
IOC 容器
什么叫 ioc 容器?
如果把在 Noba 中提供某方面功能的叫做服务1,那么把生产这些服务实体的地方叫做容器或则工厂。而服务有时候会依赖其他服务,如何能解决这些依赖关系?ioc 容器提供了一种很好的解决依赖关系的依赖注入工厂模式。
┌─────────────┐ ┌─────────────┐
│ Application │------->│IOC Container│
└─────────────┘ └─────────────┘
▲ |
| ┌────────────┴───────────┐
| │ │
| Register dependencies Resolve objects
| │ │
| ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Class │ │ Interface │ │ Object │
├─────────────┤ ├─────────────┤ └─────────────┘
│ Dependencies│<-│ Dependencies│
└─────────────┘ └─────────────┘
接下来将从四个方面来阐述 Noba 的 ioc 容器。初识 ioc 容器介绍一套完整的 ioc 容器代码,从创建到注册到使用。创建服务介绍如何创建一个 Noba 服务。注册服务介绍如何把创建的服务注册到 ioc 容器中。创建服务实体介绍如何通过容器创建出服务实体,并使用服务实体实现该有的服务。
初识 ioc 容器
- 新建的 noba 项目
mkdir noba_project cd noba_project - 在
services下新建backtest.py文件如下# services/backtest.py class Indicators(object): def __init__(self, *args): super(Indicators, self).__init__(*args) def simple_moving_average(self, datas, period=5): return sum(datas[0:period])/period class Backtest(object): def __init__(self, ind: Indicators, *args): self.ind = ind def run(self, datas): today_close = datas[4] if self.ind.simple_moving_average(datas) > today_close: print('Five days sma cross close') else: print('Five days sma not cross close') - 修改
main.py如下:# main.py from noba import core if __name__ == '__main__': backtest = core.make('services.backtest.Backtest') close = [1.9, 1.3, 2.5, 3.1, 2.1] backtest.run(close) - 运行 main.py
python main.py
创建服务
* 以 初识 ioc 容器 中代码为例:假设有一个量化回测类依赖于某个指标类
# services/backtest.py
class Indicators(object):
def __init__(self, *args):
super(Indicators, self).__init__(*args)
def simple_moving_average(self, datas, period=5):
return sum(datas)/period
# Backtest 依赖于 Indicators类,所以在 __init__ 中进行依赖注入
class Backtest(object):
def __init__(self, ind: Indicators, *args):
self.ind = ind # 容器会自动解决依赖关系,获得 Indicators 的实例
def run(self, datas):
today_close = datas[4]
if self.ind.simple_moving_average(datas) > today_close:
print('sma cross close')
else:
print('sma not cross close')
- 在服务(Backtest)的 __init__ 中通过
ind: Indicators方式注入依赖(Indicators)。但容器不一定要解决依赖,也可以简单用作实例化的目的。比如:ind = core.make(Indicators) # 等同于 ind = Indicators() - 依赖和服务可以不在
main.py文件中。甚至依赖和服务也不需要在一个文件里
注册服务
* 注册时可以用服务或接口的路径字符串,比如 'services.backtest.ThreeDayBacktest' 就是一个路径字符串。也可以通过 import 服务或则接口,然后用该服务或接口进行注册。推荐使用路径字符串。
-
通过服务别名注册2
- 编辑
config/core_config.json中aliases值。举例:
*注意:服务别名注册默认在创建服务实体时是单例模式。可以通过如下方式取消单例模式"aliases": { "backtest": "services.backtest.Backtest" }"aliases": { "backtest": ["services.backtest.Backtest", false] } - 编辑
main.py# backtest = core.make('services.backtest.Backtest') backtest = core.make('services') # 因为有了别名,所以直接可以通过别名创建服务实体
- 编辑
-
通过绑定注册3。你可以通过
bind,singleton,instance绑定接口到服务或则别名到服务。在bind,singleton绑定时,还可以绑定一个函数-
修改
services/backtest.py如下# services/backtest.py from abc import ABCMeta, abstractmethod class BacktestAbs(object, metaclass=ABCMeta): @abstractmethod def run(self): pass class Indicators(object): def __init__(self, *args): super(Indicators, self).__init__(*args) def simple_moving_average(self, datas, period): return sum(datas[0:period])/period class ThreeDayBacktest(BacktestAbs): def __init__(self, ind: Indicators, *args): self.ind = ind def run(self, datas): today_close = datas[2] if self.ind.simple_moving_average(datas, period=3) > today_close: print('Three days sma cross close') else: print('Three days sma not cross close') class FiveDayBacktest(BacktestAbs): def __init__(self, ind: Indicators, *args): self.ind = ind def run(self, datas): today_close = datas[4] if self.ind.simple_moving_average(datas, period=5) > today_close: print('Five days sma cross close') else: print('Five days sma not cross close') -
bind和singleton的区别仅仅在于创建服务实体时是不是单例模式。示例:修改main.py如下# main.py from noba import core if __name__ == '__main__': # 绑定 BacktestAbs 接口到 ThreeDayBacktest 服务 core.bind('services.backtest.BacktestAbs', 'services.backtest.ThreeDayBacktest') # 绑定 BacktestAbs 接口到 FiveDayBacktest 服务 # core.bind('services.backtest.BacktestAbs', 'services.backtest.FiveDayBacktest')* tips: 觉得接口名或路径字符串太长?还可以通过绑定接口到别名的方式减少创建服务实体时的麻烦。例如:
# main.py from noba import core if __name__ == '__main__': # 绑定 BacktestAbs 接口到 ThreeDayBacktest 服务 core.bind('services.backtest.BacktestAbs', 'services.backtest.ThreeDayBacktest') core.bind('BacktestAbs', 'services.backtest.BacktestAbs') # make 的用法见创建服务实体 # core.make('BacktestAbs') # 不再需要 core.make('services.backtest.BacktestAbs') -
instance绑定接口或则别名到一个实例# main.py from noba import core if __name__ == '__main__': three_day_backtest = core.make('services.backtest.ThreeDayBacktest') core.instance('services.backtest.BacktestAbs', three_day_backtest) -
绑定函数为创建服务实体时提供了更多操作空间
# main.py from noba import core def ret_services(core): print('绑定接口或别名到函数') three_day_backtest = core.make('services.backtest.ThreeDayBacktest') return three_day_backtest if __name__ == '__main__': core.bind('services.backtest.BacktestAbs', ret_services)
-
-
通过服务提供者注册。服务提供者是绑定服务的更加工程化实现方式。
register用于服务绑定。绑定方法同第 2 点。boot用于服务提供者的其他引导工作,会在所有服务提供者的注册工作完成后运行-
修改
services/backtest.py同绑定环节 -
新建
provider/backtest_provider.py文件如下:# provider/backtest_provider.py class BacktestProvider(): def __init__(self, core): self.__core = core def register(self): # 绑定 BacktestAbs 接口到 ThreeDayBacktest 服务 self.__core.bind('services.backtest.BacktestAbs', 'services.backtest.ThreeDayBacktest') # 绑定 BacktestAbs 接口到 FiveDayBacktest 服务 # self.__core.bind('services.backtest.BacktestAbs', 'services.backtest.FiveDayBacktest') return self def boot(self): pass -
修改
config/core_config.json中providers值如下:{ "providers": ["provider.backtest_provider.BacktestProvider"] }
-
创建服务实体
* 通过容器创建服务实体有三种等价方式:core.make()、core()、core[]。无论何种方式都能解决依赖注入问题
-
没有经过注册的服务,也可以直接通过容器创建服务实体。* 创建对象可以是一个服务的路径字符串,比如
'services.backtest.ThreeDayBacktest'。也可以是通过import服务。推荐使用路径字符串。# main.py from noba import core if __name__ == '__main__': # 假设 ThreeDayBacktest 没有通过服务别名、绑定、服务提供者进行过注册,仍然可以直接通过容器创建出服务实体 three_day_backtest = core.make('services.backtest.ThreeDayBacktest') -
通过服务别名注册的服务。沿用注册服务第 1 点的例子
# main.py from noba import core if __name__ == '__main__': backtest = core.make('backtest') close = [1.9, 1.3, 2.5, 3.1, 2.1] backtest.run(close) # 运行 main.py 会打印出下面信息 # Five days sma cross close -
通过绑定注册的服务。沿用注册服务第 2 点的例子
# main.py from noba import core if __name__ == '__main__': backtest = core.make('services.backtest.BacktestAbs') close = [1.9, 1.3, 2.5, 3.1, 2.1] backtest.run(close) # 运行 main.py 会打印出下面信息 # Three days sma not cross close -
通过服务提供者注册的服务。沿用注册服务第 3 点的例子
# main.py from noba import core if __name__ == '__main__': backtest = core.make('services.backtest.BacktestAbs') close = [1.9, 1.3, 2.5, 3.1, 2.1] backtest.run(close) # 运行 main.py 会打印出下面信息 # Three days sma not cross close
一个服务是一个类,也可以是一个函数或则一个 python 模块等
服务别名的作用是用别名全局代替服务。这样可以方便的在任何地方用较短的路径创建服务实体
绑定注册为面向接口编程提供一种便捷方式
事件服务
Noba 的事件服务目前还比较简单,只有一些简单的事件订阅和发布功能。一次完整的事件驱动分为这三步:首先需要创建事件;然后订阅该事件;在事件发生时通知订阅者。
创建事件
要创建事件需要先通过 ioc 创建事件服务,然后通过该服务创建包含事件的 Hub
- 创建事件服务:
# main.py from noba import core if __name__ == '__main__': event = core.make('event') - 创建事件:
事件被包裹在 Hub 中的,一个 Hub 可以有多个事件。该 Hub 可以是一个命名 Hub,命名的目的是方便管理 Hub,但这并不是强制的。创建命名 Hub 的方法有两个(见代码中方法一和方法二)# main.py from noba import core if __name__ == '__main__': event_service = core.make('event') # 创建一个命名为 'cross over' 的 Hub 方法一。该 hub 包含两个事件:'cross close price', 'cross open price' cross_over_hub = event_service.hub(['cross close price', 'cross open price'], "cross over") # 创建一个命名为 'cross over' 的 Hub 方法二。该 hub 包含两个事件:'cross close price', 'cross open price' cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over") - 关于 Hub 的一些操作:
-
通过事件服务获取所有 Hub
# main.py from noba import core if __name__ == '__main__': event_service = core.make('event') cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over") all_hub = event_service.get_all_hub() -
事件服务通过名字获取某个 Hub
# main.py from noba import core if __name__ == '__main__': event_service = core.make('event') cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over") hub = event_service.get_hub('cross over') print(cross_over_hub == hub) # True -
获取 Hub 的所有事件
# main.py from noba import core if __name__ == '__main__': event_service = core.make('event') cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over") cross_over_hub_event = cross_over_hub.get_events() print(cross_over_hub_event) # ['cross close price', 'cross open price'] -
获取 Hub 名字
# main.py from noba import core if __name__ == '__main__': event_service = core.make('event') cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over") hub_name = cross_over_hub.get_name() print(hub_name) # cross over -
从事件服务中删除 Hub 有两种方式。在 Hub 调用
drop_me方法;或则调用事件服务的drop方法# main.py from noba import core if __name__ == '__main__': event_service = core.make('event') cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over") # 方法一 cross_over_hub.drop_me() # 方法二 event_service.drop('cross over') -
通过 Hub 获取事件服务
# main.py from noba import core if __name__ == '__main__': event_service = core.make('event') cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over") service_obj = cross_over_hub.manager print(service_obj == event_service) # True
-
订阅事件
通过 watch 方法可以订阅在 Hub 中定义的事件。watch 接受 3 个参数:事件名 、 回调函数,回调函数可以接受事件通知时传递的数据。第 3 个参数是个布尔值 ,决定该订阅是否可以多次监听。默认为 False,只监听一次。
# main.py
from noba import core
if __name__ == '__main__':
event_service = core.make('event')
cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over")
cross_over_hub.watch('cross close price', lambda data:print(data), True) # True 表示该订阅可以多次监听。False 是只监听一次
上面是面向过程的事件订阅,还可以面向对象方式来订阅事件(订阅者模式)
from noba import core
event_service = core.make('event')
class Purchase(event_service):
def subscribe(self, event):
cross_over_hub = self.get_hub('cross over')
# 订阅事件
cross_over_hub.watch(event, lambda data:print(f"moving average price is {data['moving_average_price']}, close price is {data['close_price']}。cross over!"), True)
if __name__ == '__main__':
# 创建一个命名为 cross over 的hub,该 hub 包含两个事件:'cross close price', 'cross open price'
cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over")
Purchase().subscribe('cross close price')
事件通知
通过 fire 方法可以触发定义在 Hub 中的事件。fire 传入两个参数:事件名 和 数据。数据会传递给订阅者的回调函数中。如下代码会打印出:"moving average price is 12, close price is 10。cross over!"
# main.py
from noba import core
if __name__ == '__main__':
event_service = core.make('event')
cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over")
cross_over_hub.watch('cross close price', lambda data:print(f"moving average price is {data['moving_average_price']}, close price is {data['close_price']}。cross over!"), True)
cross_over_hub.fire('cross close price', {"moving_average_price":12, "close_price":10})
订阅者模式下的事件通知:
# main.py
from noba import core
event_service = core.make('event')
class Purchase(event_service):
def subscribe(self, event):
cross_over_hub = self.get_hub('cross over')
# 订阅事件
cross_over_hub.watch(event, lambda data:print(f"moving average price is {data['moving_average_price']}, close price is {data['close_price']}。cross over!"), True)
if __name__ == '__main__':
# 创建一个命名为 cross over 的hub,该 hub 包含两个事件:'cross close price', 'cross open price'
cross_over_hub = event_service.hub(['cross close price', 'cross open price']).name("cross over")
Purchase().subscribe('cross close price')
cross_over_hub.fire('cross close price', {"moving_average_price":12, "close_price":10})
* 当然通知也可以用面向对象来改写,只需要继承事件服务就可以,代码略
管道服务
虽然用 Python 生成器很容易就实现一个管道服务功能,但 Noba 的管道服务还是要灵活一些。目前管道功能还是比较简单,仅仅实现了通过管道对某个对象1顺序进行加工处理的功能。
一次完整的管道服务代码包括这几个步骤:创建加工类、创建管道服务、通过管道加工对象。最后会介绍管道的进阶用法
创建加工类
加工类是指一系列对需要被加工对象进行处理的类。本例在 pipeline 文件夹下创建 handle_data.py 代码如下:
# pipeline/handle_data.py
class ChangeFieldName():
def handle(self, data, next, *what):
print("更改列名")
# 省略具体加工代码
return next(data)
class ChangeDataType():
def handle(self, data, next, *what):
print("更改数据类型")
# 省略具体加工代码
return next(data)
class RepeatRowData():
def handle(self, data, next, *what):
print("删除重复行")
# 省略具体加工代码
return next(data)
class ExceptionData():
def handle(self, data, next, *what):
print("处理异常数据")
# 省略具体加工代码
return next(data)
class MissingData():
def handle(self, data, next, *what):
print("处理缺失数据")
# 省略具体加工代码
return next(data)
创建管道服务
管道服务是通过 ioc 容器创建出来的
# main.py
from noba import core
if __name__ == '__main__':
pipeline_service = core.make('pipeline')
通过管道加工对象
Noba 的管道目前是单向管道。通过管道可以把加工类顺序作用在需要被加工的对象上
# main.py
from noba import core
def target(data):
# 省略一些逻辑代码
return data
if __name__ == '__main__':
pipeline_service = core.make('pipeline')
# 通过 ioc 创建 pandas 服务
pd = core.make('pd')
# processed_data 为处理前的原始数据
raw_data = pd.DataFrame([[10.2, 9.5, None, 9.2],[11, 8.5, None, 9.1],[None, None, None, None],[12.3, 13, 13.1, 12.1]],columns=['open', 'close', 'high', 'low'])
# pipeline 为处理管道
pipeline = ['handle_data.ChangeFieldName', 'handle_data.ChangeDataType', 'handle_data.RepeatRowData', 'handle_data.ExceptionData', 'handle_data.MissingData']
# processed_data 为处理后的数据
processed_data = pipeline_service.send(raw_data).through(pipeline).then(target)
管道的进阶用法
- 在第 3 个例子中定义
pipeline中的加工类时并没有使用完整的路径2。原因是 Noba 默认加工类都是放在pipeline文件夹下的。可以通过如下代码来更改默认路径。# main.py pipeline_service.folder('your pipleline folder') - 默认加工类的处理方法是
handle。可以通过如下代码来更改处理方法。# main.py pipeline_service.via("handle_pipeline") - 定义管道时可以为加工类传递额外参数。如下面代码就给
ChangeFieldName的handle方法传递了参数('close price', 'open price')。# main.py pipeline = ['handle_data.ChangeFieldName:close price,open price', 'handle_data.ChangeDataType', 'handle_data.RepeatRowData', 'handle_data.ExceptionData', 'handle_data.MissingData']
对象可以是一个数据对象(比如需要对某个 dataframe 填补空值、修正异常值等数据清理)或则其他任何需要顺序加工的对象
以 ChangeFieldName 类为例子,完整路径应该是 pipeline.handle_data.ChangeFieldName。但在第 3 例时,定义的路径是 handle_data.ChangeFieldName