快速上手
本章快速上手只是帮助你整体浏览 Noba 的工作流。详细内容会在后续各章节中进行介绍。
安装
pip install noba
初始化 Noba 项目
mkdir noba_project # 名字随意取
cd noba_project
noba init
* 下面内容是 noba init 初始化过程。本章用 csv 文件示例。除了 csv 和 orcl-1995-2014.txt ,其他直接回车用默认的就好
Let's init Noba project...
connector(mysql/sqLite/postgresql/...) : csv
host(localhost/...) :
port(3306/...) :
database : orcl-1995-2014.txt
username :
password :
format(dataframe/list) :
Demo 数据
- 下载:orcl-1995-2014.txt
- 把 orcl-1995-2014.txt 移动到
noba_project/migrate目录下
编辑 main.py
* 初始化 Noba 项目后,mainy.py已经存在,把下面内容覆盖到 main.py 中
from __future__ import (absolute_import, division, print_function, unicode_literals)
import pandas as pd
from noba import core
from datetime import datetime
bt = core('bb')
class My_PandaData(bt.feeds.PandasData):
params = (
('nullvalue', 0.0),
('dtformat', '%Y-%m-%d'),
('high', 1),
('low', 2),
('open', 0),
('close', 4),
('volume', 5),
('fromdate', datetime(2000, 1, 1),),
('todate', datetime(2001, 2, 28)),
('openinterest',None),
)
class MyStrategy(bt.Strategy):
def __init__(self):
sma1 = bt.indicators.SMA(period=11, subplot=True)
bt.indicators.SMA(period=17, plotmaster=sma1)
bt.indicators.RSI()
def next(self):
pos = len(self.data)
if pos == 45 or pos == 145:
self.buy(self.datas[0], size=None)
if pos == 116 or pos == 215:
self.sell(self.datas[0], size=None)
if __name__ == '__main__':
cerebro = bt.Cerebro()
cerebro.addstrategy(MyStrategy)
db = core('db')
data = db.set_index('Date').get()
data.index = pd.to_datetime(data.index)
datafeed = My_PandaData(dataname = data)
cerebro.adddata(datafeed, name='orcl-1995-2014')
cerebro.addanalyzer(bt.analyzers.SharpeRatio)
cerebro.run()
p = bt.Bokeh()
cerebro.plot(p)
运行项目
python main.py
图表展示
* 下面是运行量化回测后的部分截图
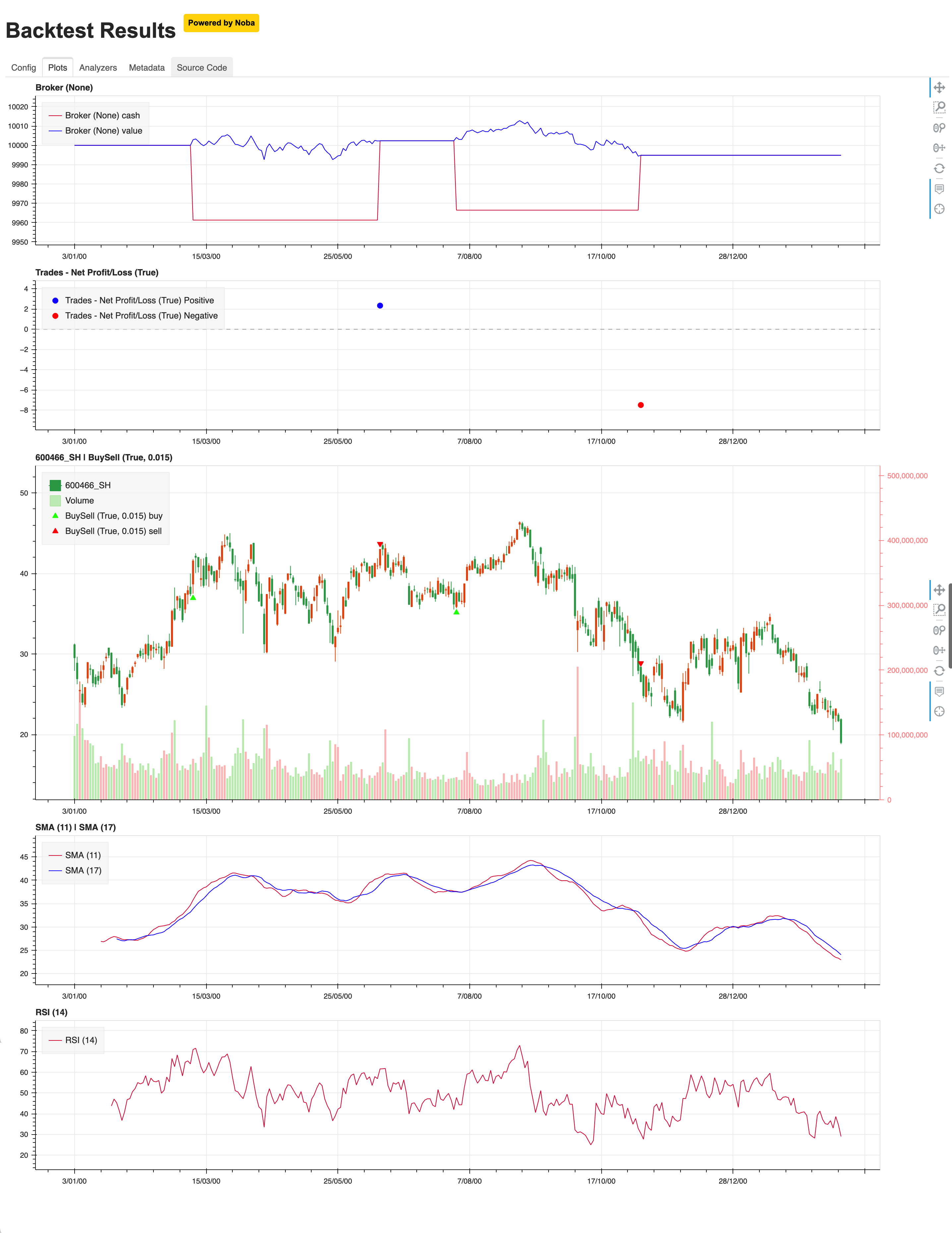
图表展示